
How to crawl the web

I usually work with CMS and, from time to time, there's the same old question: what's their marketshare? Joomla claims to be the 2%, WordPress something around 27%. Is there a way to get some solid data and fix this issue once and for all?
Well, the answer is simple: let's crawl the web and count how many sites are using a specific technology.
A man with a plan
As usual, let's break a single complex task into a set of small and simple steps. Generally speaking, this is what I had to do:
- Build up a list of sites to visit
- Identify the technologies they are running. If any CMS is used, try to detect the correct version
- Store the results
- (Optional) Make the whole process scalable
The results
This will be a quite long article, so if you're only interested in the original question, here's the results of my work.
Number of scanned sites 6,447,715
Number of Joomla! sites 196,211
Number of WordPress sites 1,025,064
Total data received 3,311.324 GB
Please note: When this research was performed, the last available version for Joomla! was 3.6.5 and for WordPress 4.7.1
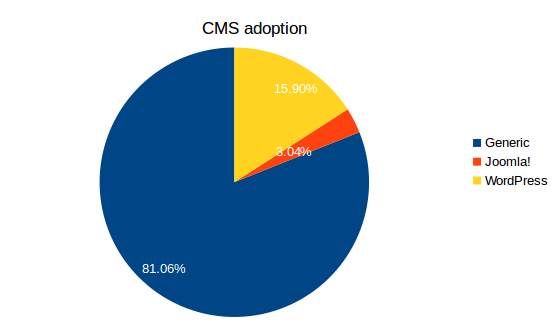
Let's look how Joomla! versions are distribuited:
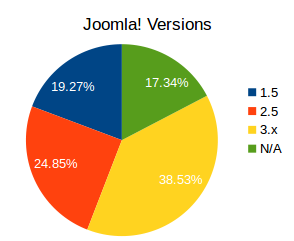
There's an astonishing amount of old 1.5 versions (which are completely unsafe). The large amount of not detected versions contain old 1.0 sites and sites with 1.6/1.7 installations. I tried to revisit such sites, but it required too much time to passively fingerprint them using JScanner and the improvement was really minimal. We can treat them as a "black box"; anyway, even if they are all 3.x installation, that doesn't change the fact that a large amount of sites are still using old, legacy versions.
Now, let's drill down into the specific versions:
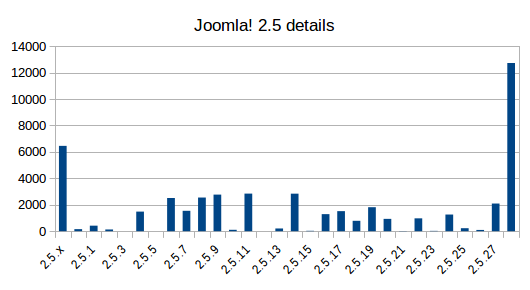
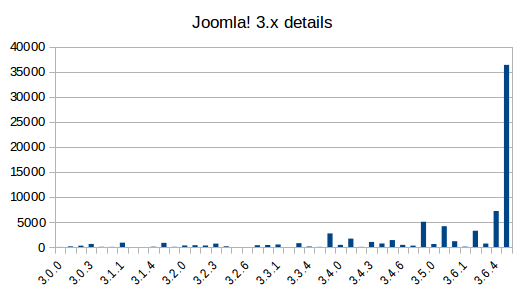
Even in this case, we can see there are several sites that aren't updated to the latest version.
Let's move on WordPress:
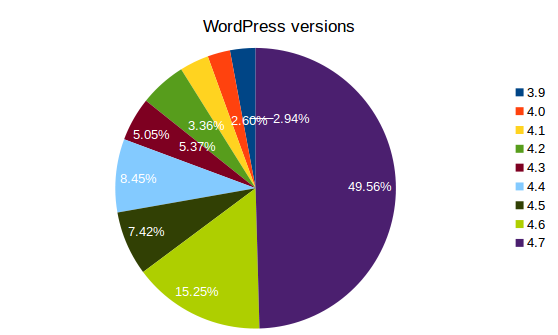
Here things are a little more complicated, since there are several "major" releases and creating a full chart for all of them will only complicate the layout of this article. Moreover, I got a lot of "undetected" versions: about 20%, but they're not reported on the chart for clarity sake.
However, it's really easy to spot that almost 50% of all detected WordPress installation aren't using the last available version.
If you think about it, this is something terrifying.
With my script I simply collected the current version of the two major CMS; a malicious user could use this data to create a list of targets and use old, well known and reliable exploits to compromise all of them.
Once again, the best way to protect your site is to keep it updated.
Now that your curiosity has been satisfied, let's move into the technical details.
Technical details
At the beginning this seemed a quite simple task, but during the journey I had to face several challanges and confront myself with some new technologies I never used before. The whole system was running on Amazon AWS instances, glued together with Redis, DynamoDB and bits of NodeJS.
But let's start from the beginning.
1: Find the sites to crawl
Just think about it: how can you find the list of all online sites?
That's something not so easy: there are some info online, but all require some intensive scraping. For example, in one blog post I found, the author started from Alexa 1 million top domains and then started following all links. Reading about his work, it seems there was a lot of effort in creating a list of unique links: at the end of the day I only need the home page to identify the contents, I don't need to scrape the whole site.
After some researches, I found the Common Crawl project. They regularly scrape the web and distribute the results of their work; in their last release of April 2017 they crawled just a little less of 3 billion of pages.
The most interesting thing is how they organize their work: you can download the contents of every page, but there's a list of all the robots.txt files they found, too. Since I was interested only in the domain name, that was the perfect resource for me.
Contents of robots.txt crawl is something like this:
WARC/1.0 WARC-Type: request [... snip ...] WARC-Target-URI: http://0n44l.recentcrs.com/robots.txt GET /robots.txt HTTP/1.0 [... snip ...] WARC/1.0 WARC-Type: response [... snip ...] WARC-Target-URI: http://0n44l.recentcrs.com/robots.txt WARC-Payload-Digest: sha1:PLSICP2F4HEGTUYUGSYFIWHQOSSFJJKU WARC-Block-Digest: sha1:JHB3WR2GHM7AK76S7SU2V43HMTDFR7OL HTTP/1.1 200 OK [... snip ...]
This means that I can extract the full domain name from WARC-Target-URI.
2: Identify the CMS
This was the most difficult part. Wappalyzer is doing a great job on identifying server and client technologies; since there are several ports of it under Python, I thought I could easily use them.
I've never been so wrong.
Long story short, Wappalyzer is doing a great job because it runs inside your browser and has a complete view of the site you are visiting. On the other end, while using a Python script, it is simply downloading some text and trying to analyze it. That's not enough: for example, while trying to identify a Joomla installation, Wappalyzer checks if the global Javascript variable Joomla is declared. This is something that only a browser can do.
So goodbye Python ports, welcome PhantomJS.
PhantomJS is an headless browser, used to run integration tests without the need to spin a whole graphical environment. There's only one small catch: Python integration driver is no more maitained and it's completely broken.
Goodbye sanity, welcome madness, my old friend.
Trying to stick together Python, PhantomJS, multi-thread processes while dealing with broken or non-responding sites is like trying to perform brain sugery on a roller coaster. Under alchool.

The only solution was to actually spawn the Wappalyzer script using NodeJS, which in turn would open the URL in PhantomJS and spit out the result on the console. Then parse it and record the result.
The only downside happens when a site is not responsive, so the Python thread gets stuck waiting for an answer that will never arrive. To overcome this, I setup a CRON job that would kill all instances of my Python script and PhantomJS and start everything again.
Stupid? Yes. Effective? Hell yes!
3: Store the results
The first answer could be the good old Shove it in MySQL!. However there are several constrains that should be considered.
First of all, MySQL is a relational database: this means that you have to plan a database schema and then stick it to it. Honestly this project was like a jam session, so I really didn't know which info I had to store and retrieve.
Then we have to consider the size: in my head, I only wanted to crawl the web for a couple of weeks or when my budget (about 60€) ran out. I really didn't know how many rows I could find, but we were talking about millions.
So I decided to fallback to NoSQL, just to explore it and get more experience.
At the beginning I thought about MongoDB; sadly Amazon at the moment is not offering a managed version of it. This means that I had to spin, configure and maintain a new server only to host the database.
Luckly, Amazon offers its own schemaless database DynamoDB.
It's completely managed, there's no need to worry about configuration or load handling: you simply put the connection details and it works. As final note, it's fully integrated inside their Python package Boto3, so it's very easy to use.
Again, there's a small catch: DynamoDB works with the concept of "credits". You can assign some credits to the tables for read/write operations per seconds; once you ran out, your operations are slowed down (throttled) and finally you get a fatal error.
Moreover it's very easy to query for the primary ID, but if you need to do some kind of searches, things get complicated: you'll have to perform a full table scan, consuming all your credits.
Anyway, at the end of the day it was the right choice, since I had one thing less to manage and I could focus on scraping.
4: Scaling a.k.a. "wrapping all together"
So these are the building blocks, but how can you create a modular environment, that's easy to scale?
Please let me introduce my friend Redis.
The final setup is something like this:
1 "manager" server
The manager runs an instance of Redis, containing the sites to analyze. If the amount of links is too low, it will grab the latest file from Common Crawl Amazon S3 repository containing the list of robots.txt files, extract the URLs and push them into the Redis stack.
Moreover it will monitor the results reported from the analyzers and perform batch updates to the DynamoDB database. In this way we can combine requests and lower the amount of credits used.
N "analyzer" servers
Analyzers will do the dirty job: multiple threads will pop an URL from Redis stack, fire Wappalyzer script (that will spawn an instance of PhantomJS), wait for the result and report back inside Redis.
Opening and closing multiple browsers in fast sequence will create issues in the long run, so to avoid any problems a CRON job kills everything every 90 minutes and starts again. A dirty but working solution.
This setup is quickly scalable, since the amount of analyzers can be easily scaled up or down, setting the amount of threads any analyzer is currently running.
Conclusions
It started as quick project and it turned out to be quite an hell: however I'm very happy of it. I was able to grasp some details about Redis and NoSQL configuration, especially with DynamoDB.
As a final note, I know I only crawled a tiny fraction of the web, so most likely results are a little biased, however they show an interesting trend:
Old versions are hard to die
Related Posts



 "
"
Comments: